Alpha launch of Memoire
Today we are announcing our newest product Memoire: a document retrieval pipeline “as-a-service”.
Document retrieval has many applications, including search, recommendation systems and more. The most notable application of such a pipeline is with LLMs and RAG: due to security and technology limitations, LLMs do not have omniscient knowledge, especially when this is proprietary (ex: internal documentation).
So RAG allows your LLM application to have context awareness (meaning more accuracy and greatly reduced hallucinations) and provide this information securely (for example by checking access rights).
Building your RAG

If you want to implement this in your application, you will need a vector database and/or a search database. Those solutions are very good at advertising how to use them for storing vectors. However, what they don’t tell you about is the real cost of building a fully functional pipeline.
A basic pipeline requires a lot more consideration and time than just sending a vector. At the bare minimum, you will have to:
- Pull data from a source (in the figure below we assume those are files, but it can be CRM records, chats, websites, …)
- Parse data from documents if this is not raw text (PDFs, Office, etc)
- Chunk the documents for vector search & extract keywords for full-text search
- Choose and make an embedding model work
- Choose a vector database, choose a vector search algorithm, choose a document storage, and build all the connections to those solutions
- Sync your search database with a document storage and/or a regular database (and make sure they are updated on all CRUD operations)
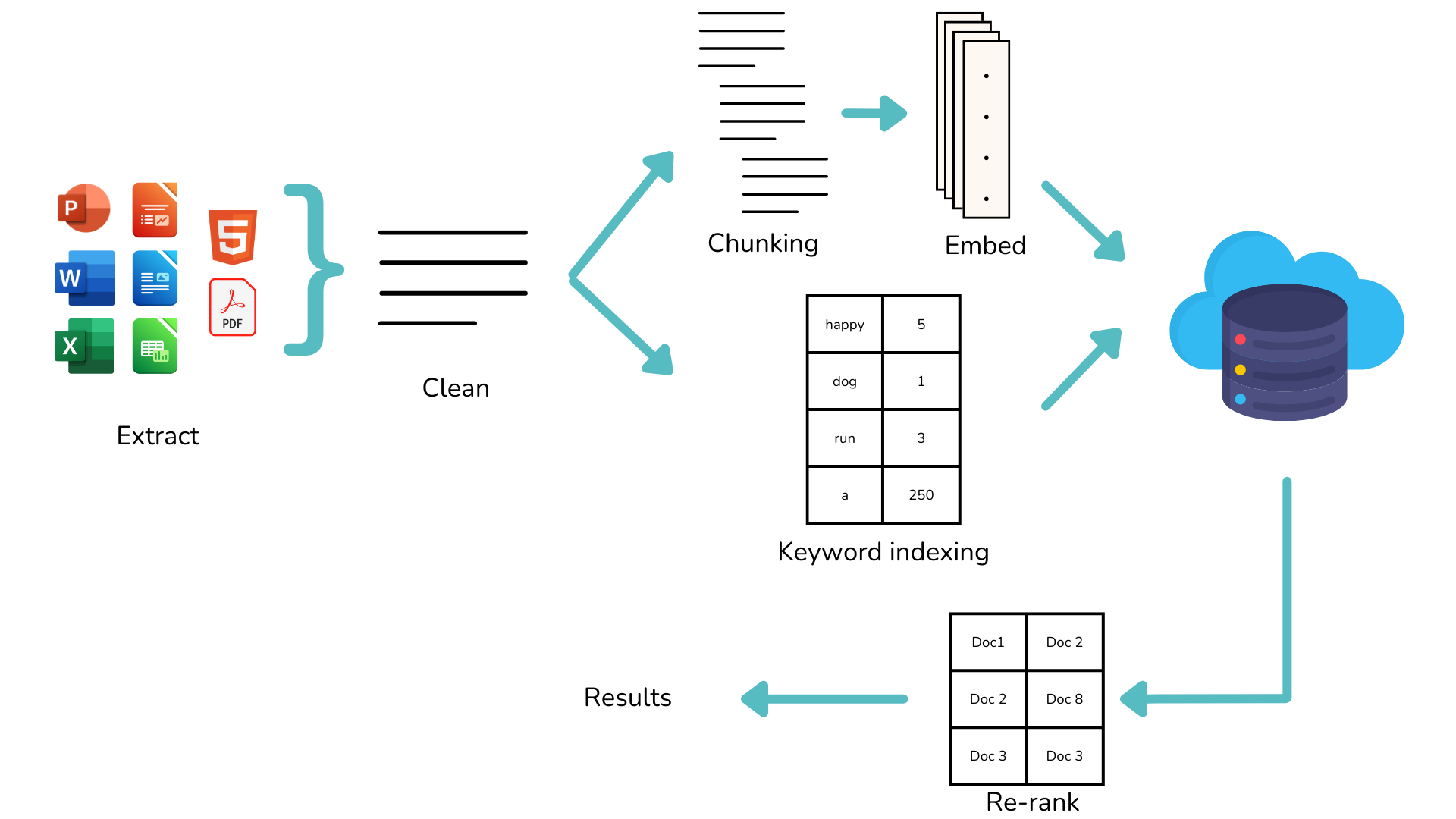
With a good developer, you can get this working in 3 to 6 weeks… But a good developer is expensive, and depending on where you live, this can be quickly an investment of $6k to $10k... Just to get started.
And on top of those proof of concept steps, you will also need to:
- Make sure your LLM works as expected
- Scale and maintain the pipeline
- Continue building your main application
You can also add that the industry is evolving extremely fast, with new developments every month. If you want to stay up to date, you will require even more investment in time and workforce…
…That’s where we come in…
A* Logic: Memoire
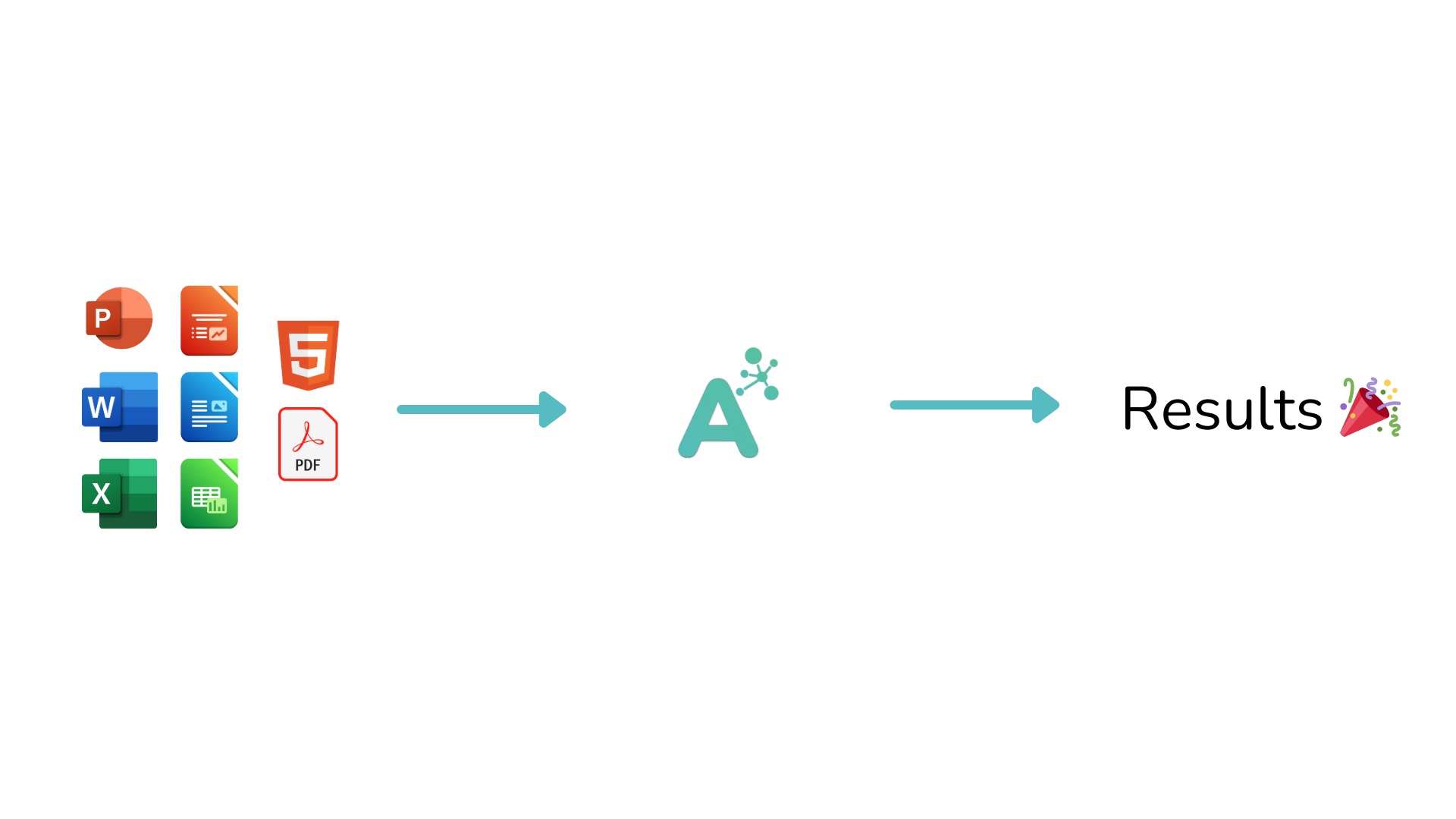
If code is more speaking for you, here is a quick snippet:
pythondocuments = [ { "documentID": "word", "url": "https://demo.com/recipe.docx" }, { "documentID": "excel", "url": "https://demo.com/techniques.xslx" }, ] index_documents(documents) search('I want to cook a recipe with carrots and bacon')
Memoire is a document retrieval as-a-service: set up once and forget. Simply send the documents, and query when you need to.
Everything else is done for you: Memoire ingest the most common document types, store the originals so you won't need a separate storage, and our team brings and maintain state of the art algorithms such as hybrid search or auto chunking.
All this so you can focus on the fun and important stuff: amaze your users!
Next steps
You can find the documentation on GitHub. You are welcome to contribute and star the project as well.
We are bootstrapping A* Logic (A-star logic), so Memoire is source-available: free for hobby use but paid for production. We will change to open-source/open-core license as soon as we are default alive.
Happy coding!
M.