State of the art RAG in one day
From data extraction to search, Memoire handle all the complexity so your team can innovate faster and focus on what really matters: your customer's experience.
From data extraction to search, Memoire handle all the complexity so your team can innovate faster and focus on what really matters: your customer's experience.
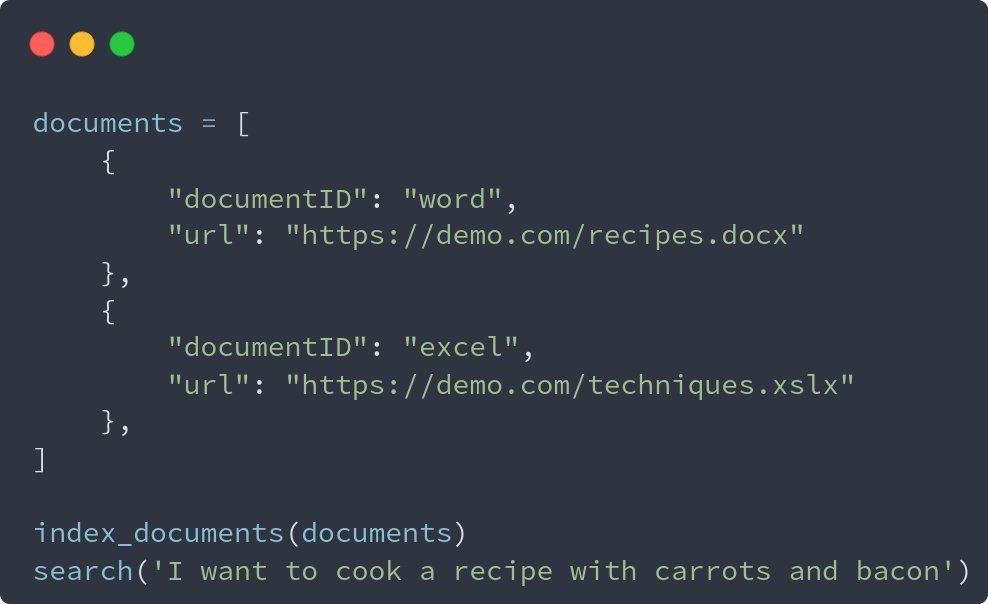
RAG Pipelines are an already solved problem, yet a good, accurate and fast pipeline still take several months to implement.
Reinventing the wheel takes time.
Time you could spend on more urgent matters, and engineers' time is expensive precious.
You know, that pesky bug uncaught in QA?
You guessed it, you need maintenance as well
Your business is getting traction, congrats!
Now who's going to extinguish the database on fire?
Great developer experience
= Less time to deploy
= Faster to market
= Faster to innovate
Get state of the art document retrieval such as hybrid search, auto chunking, and more (our team stay up to date with the best in the industry for you).
10k, 100k, or millions of documents with no added work on your end.
Build your document retrieval in four steps (yes it’s that easy)
Send multipart data or downloadable urls, in bulk or one by one.
Memoire supports the most popular formats, with more added with every update.
Your documents are ready to be fetched. Memoire also save the original document, so you won't need separate storage

That's it!

Transparency is important to us, we are building in the open: Star us on Github, or Read our handbook
We are not open source yet! But plan to move to an open-core model once we are default-alive.
Follow our development with our newsletter:
A monthly-ish digest of our announcements, engineering and startups learning posts